コンピューターって何?と考えた時にCPUという言葉が浮かび易いと思いますが、CPUの動作って意外と知らないことが多いですよね。
そもそも半導体のレベルで「0と1」が表現され、それを組み合わせて高速で演算をしているが、目に見えないので、捉えるのが難しいです。
ですので、今回はこのCPUの動きを解説します!
CPUの命令実行サイクルとは?
先ず、CPUは常時膨大な数の命令を1つずつ高速に処理しています。メモリなどの記憶装置に読み込まれたプログラムのデータから一つずつ命令を取り出して、それを解読します。そして、その命令の中から必要なデータの格納場所を調べてデータを読み出し、そしてデータを使って計算等を実行するという一連の手順を繰り返しています。この流れを命令実行サイクルと言います。
続いて命令実行サイクルにおける加算処理の話になります。例えば「3+5」を実行する際は「+」の加算をするという命令だけではなく、加算対象となる「3」と「5」の対象データが必要です。そのための処理として、命令部(加算)と処理部(データ)で構成され、処理対象のデータの格納場所を示す場所をアドレス部といいます。
つまり、命令は【命令部】+【アドレス部】で構成されます。
アドレス部の中の処理対象となるデータはオペランドといい、オペランドの保存場所を導き出すことを実行アドレス計算と呼ぶようです。因みに命令のことはオペコードと呼びます。
概念的に表すと、【命令部(オペコード)】【アドレス部(オペランド)】になります。
オペコードとオペランドを繋げて、それを機械語にしたもの(例えば、mov AやADD A,B)をニーモニックと呼びます。呼び方が色々出てきて難しいですね...
さて、話を戻して、命令実行サイクルには5つ段階があります。
1.命令フェッチ(Fetch):命令を主記憶から取り出し、CPUの命令レジスタに取り込む
2.命令の解読(Decode):命令コードを解読する(デコード)
3.実行アドレス計算(Address Calculation):命令対象となるオペランドの格納場所を計算して求める
4.オペランド読み出し(Read):主記憶の実行アドレスにアクセスし、オペランドを読み出す
5.命令の実行(Execution):命令を実行し、必要に応じて結果データを主記憶に書き込む
この5段階のサイクルがCPUの中で常時行われています。
CPUの実行命令サイクルに関してはこちらの記事も参考にしてみてください!
CPUの高速化技術
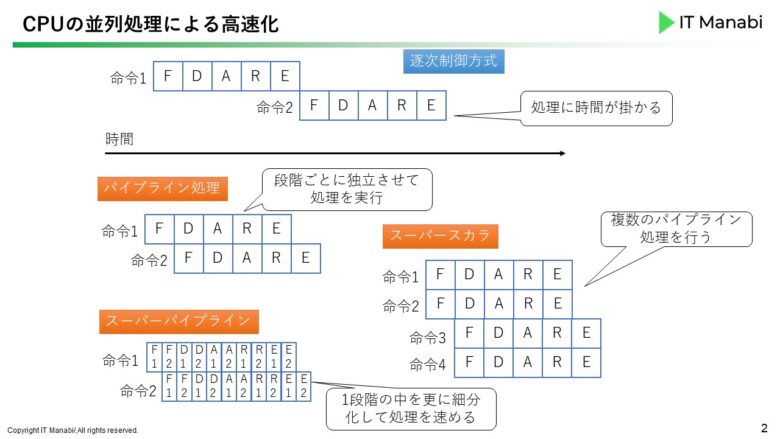
これまで説明してきた命令実行サイクル単位で、主記憶にある命令を1つずつ順番に実行する処理の方法を逐次制御方式(ちくじせいぎょほうしき)といいます。1つの命令が終わるまで、次の命令は実行されません。
そのため、ある装置が処理を実行している間、その前後の処理を担当する装置に待ち状態が発生してしまいます。
そこで待ち状態を無くすために、命令の実行中に次の命令を開始することで処理の高速化を実現する技術があります。それがパイプライン処理です。
パイプライン処理
命令実行サイクルを各段階(ステージ単位)ごとに分け、独立させて実行し、流れ作業的に、最初の命令サイクルが終わる前に、次の命令サイクルの処理を始める方式です。
スーパーパイプライン
パイプライン処理の各ステージをさらに細かく分割し、並行して実行することで、動作を高速化する方式です。
クロックを上げることによってスループットを上げる感じですね。
スーパースカラ
複数のパイプライン処理を行う回路を設けることで、同時に複数の命令を処理し、高速化する方式です。
プログラム中に、前後の命令の影響を受けずに独立して実行可能な命令があるとき、ハードウェアでこれを検出し、パイプラインに処理を割り振るのですね。
以下にそれぞれの処理イメージを作ってみました。
まとめ
今回はCPUの処理方法と速さに関して解説しました。
コンピュータの頭脳であるCPUですが、常に動き続け、様々な処理(計算)を頑張って行っているんですね。
その他、CPUの性能指標である、クロック周波数やCPI、MIPSなんて言葉や内部構造であるRISC(リスク)やCISC(シスク)なんて言葉もありますが、その説明はまた別に機会にできればと思います。
更に物理的な話であるコンデンサ?トランジスタ?は以下サイトを参照してみてください。(こちらはアナログな世界ですが面白いです!)
以上です!
参考URL)
