データベースにおいて検索に掛かる時間(性能)は非常に重要なポイントですよね。データベースのデータ量が多くなればなるほど、必要なデータを探し当てるためには時間が掛かってしまいます...
そのための対策として索引(インデックス)を作成して、利用することができます。テーブル内の一つ以上の列に対して索引を指定することで、指定された列は一定の順序で並べられますので、検索を高速に行えることになります。
今回はこの索引の作成において、キーワードとなる「ユニーク検索と非ユニーク検索」、「クラスタ検索と非クラスタ検索」に関して、その意味と違いを調べてみました!
尚、SQLを作成する方にとっては「インデックス」という言葉の方が馴染みがあるかと思いますが、この記事においては「索引」という言葉で説明します。
索引(インデックス)の基本的な仕組みとは?
先ず、下の図のテーブルを見てみましょう。通常テーブルを作成して、データを登録していくと物理的に入力された順番にデータが登録されていきます。
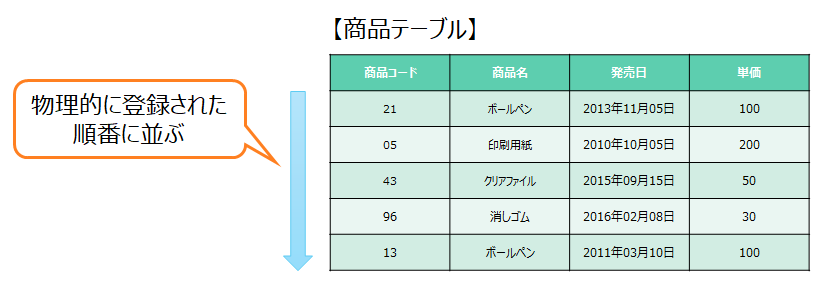
このテーブルに対して、例えばWHERE句を用いて、「商品コード13の商品」を検索した場合、その対象となるデータがどこにあるのか分からないので、1行目から最終行のデータまで全てのデータを1件ずつチェックしていくことになります。データの件数が少ない時や最初の行でデータがヒットすれば問題無いですが、行数が多くなるにつれてどんどん性能が落ちて、検索時間が長くなります。
このような検索の方法を「全件検索(フルスキャン)」と呼んだりします。
全件検索により性能の劣化を防ぐために「索引を設定(インデックスを張る)」します。
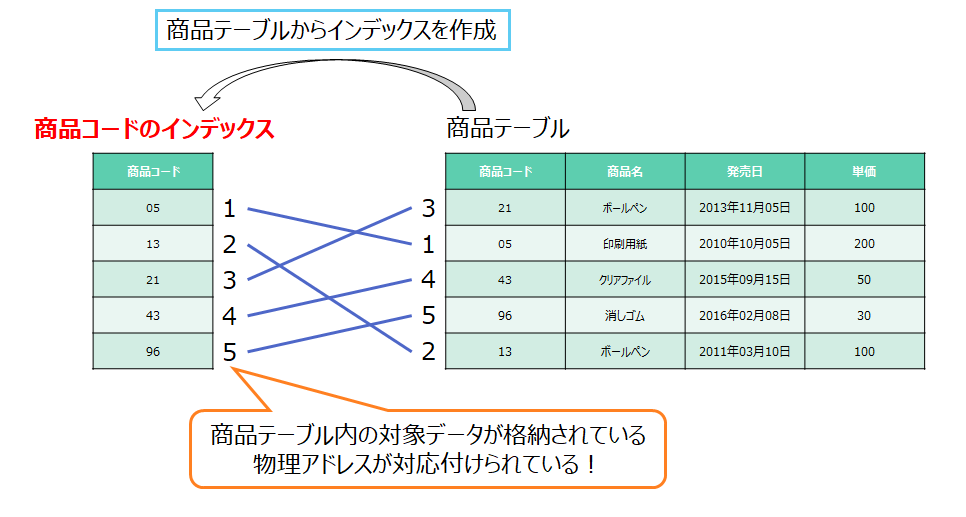
下の図のように、「商品コード」で索引を作成します。先ほどと同様にWHERE句に「商品コード13の商品」を指定して検索した場合、今度は索引を利用して効率よく商品コード13だけのデータだけを取り出すことができます。
しかも、将来的にデータの量が増えても性能は殆ど変わらないことが大きなメリットですので、データ量が増えるほど、全件検索と索引検索の性能差は開いていきます。
索引を作るSQL文は「CREATE INDEX文」で作成しますね。
ユニーク索引と非ユニーク索引の違いとは?
先程説明した索引において、ユニーク索引と非ユニーク索引という二つの種類があります。
ユニーク検索は、その索引で指定した列や列の組の値の重複を許さない索引のことで、 主キー制約やユニーク制約が指定された索引になります。つまり、ユニーク制約を付与した列に関しては自動で索引が作られるようになります。
一方、非ユニーク索引は値の重複を許す索引になります。
通常はピンポイントな値を探し出すために、ユニーク索引が使われることが多いです。
では、「非ユニーク索引が使われる時はどんな時なのか?」というと、テーブル全体から一部のレコードを効率的に抽出することが可能な時に使います。例えば、商品テーブルの商品カテゴリ(食品や衣類など)に索引を作った場合、食品には複数の種類があるため非ユニーク索引になりますが、食品の商品レコードだけを抽出するようなSQLを作った場合、効率化が実現できます!
- ユニーク索引 : 列や列の組の値の重複を許さない索引。データを一意に特定できる
- 非ユニーク索引 : 値の重複を許す索引。一部の複数レコードを効率的に抽出できる
クラスタ索引と非クラスタ索引の違いとは?
続いてクラスタ索引と非クラスタ索引の違いを説明をします。
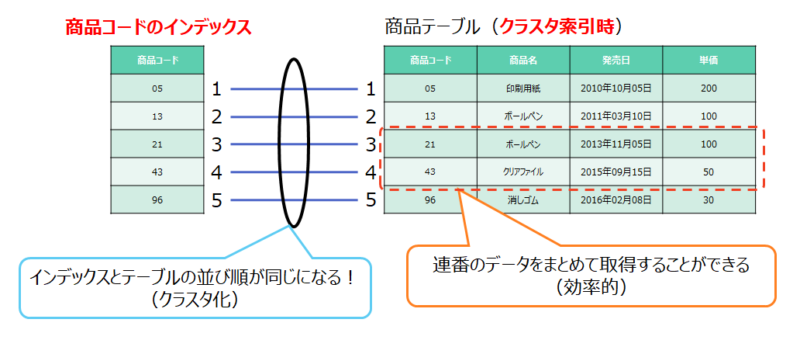
前述してますが、通常テーブルを作成した場合、データの並び順は綺麗にはなっておりません。そのために索引を別途作成して、検索の性能を上げています。一つのデータを抽出する時には先ほどのユニーク索引などで良いのですが、「ある範囲」をまとめて抽出したい時により早く検索ができる「クラスタ索引」というものがあります。
クラスタ索引を使うと、「指定した列の並びとデータの並びが同じになります」。
下の図の例だと、「商品コードの20から50までを抽出」のように連続した範囲を指定してデータを処理する時にページ単位でデータを抽出するための物理I/Oの回数を減らすことができます。
商品コードをクラスタ索引にすると、大元の商品テーブルが整列されるイメージとなります。
実際はもっと広い範囲でまとめて取得するとよりメリットが出ることになります。
反対に非クラスタ索引はクラスタ化されていない索引のことになりますので、テーブルが作成されたままの状態になります。
尚、クラスタ索引はテーブルに対して一つしか設定できず、他の索引は全て非クラスタ索引になりますので、ご注意ください。
- クラスタ索引 : 索引で指定した列の並びと実際のデータの並びを同じにすることで、ある範囲を指定した検索性能の向上を実現できる。
- 非クラスタ索引 : クラスタ索引以外の索引のこと。
まとめ
今回はデータベースの索引(インデックス)の仕組みと、ユニーク索引と非ユニーク索引の違い、クラスタ索引と非クラスタ索引の違いを調べてみました!
それぞれの索引のパターンによって、どんな検索に強いかが違うのですね。
非クラスタ索引は、クラスタ索引の対象の言葉ですが、何もしていない普通の索引のことになりますね。
別の記事でも記載しましたが、何でもかんでも索引(インデックス)を作ってしまうと、ディスク容量のムダ使いや性能劣化に繋がってしまうので、慎重に設定していく必要がありますね!
以上です!