メールを見ると文字が「?」だったり「■」だったりしている時がありますよね。これを「文字化け」と呼んだりします。
なぜ文字化けが起こるのでしょうか?それは、文字を表示するソフトがその文字を知らない、または間違った文字と解釈するからです!
文字化けをしないためには、文字を定義する文字コードや文字符号化を理解して、正しい使い方をする必要があります。
今回はこの文字コードの意味と、文字コードに関係する文字集合体と文字符号化について調べてみました!
結構奥深い話ですよー。
文字コードとは?
コンピュータの中では全てのデータを「0と1」だけで表現しております。例えば「A」だったら1バイトの「01000001」という数字の列で扱ったりしています。
この数字の羅列がどの文字に対応しているかを決めたルールが文字コードとなります。
文字コードは使っているコンピュータやOSによって違いますので、採用している文字コードが違う環境でデータを交換した時、文字を変換すると違う文字(文字化け)になってしまいます...
代表的な文字コードは以下の通りです。聞いたことがあるかと思います。
- ASCIIコード:米国規格協会が制定した1文字を7ビットで表現する文字コード。文字コードの基本となっています。半角英数字は表現できますが、漢字を表現することはできません。
- EBCDIC:IBM社が定めた文字コードで、8ビットを使って1文字を表現します。最近はあまり使われませんが、大型の汎用コンピュータなどで使っています。
- システムJISコード(S-JIS):漢字やひらがなを表現できます。日本のパソコンで古くから最も使われている文字コードです。
- EUC:拡張UNIXコードとも呼ばれ、UNIXというOS上でよく使われている日本語文字コードです。UNIX上で漢字が扱えます。
- Unicode:全世界の文字コードを一つに統一するために作られた文字コードです。当初は1文字を2バイトで表現する予定でしたが、それだと文字数が足りないので、3バイト、4バイトとどんどん拡張されています。
因みに文字コードはコンピュータの内部で使いますが、画面に表示したり印刷したりする時は人間が読める文字の形に変換する必要があります。文字コードにどんな形の文字を表示するかを決めた書体のデータをフォントといいます。
バイナリデータと文字コード、フォントの変換イメージは以下の図の感じですね。

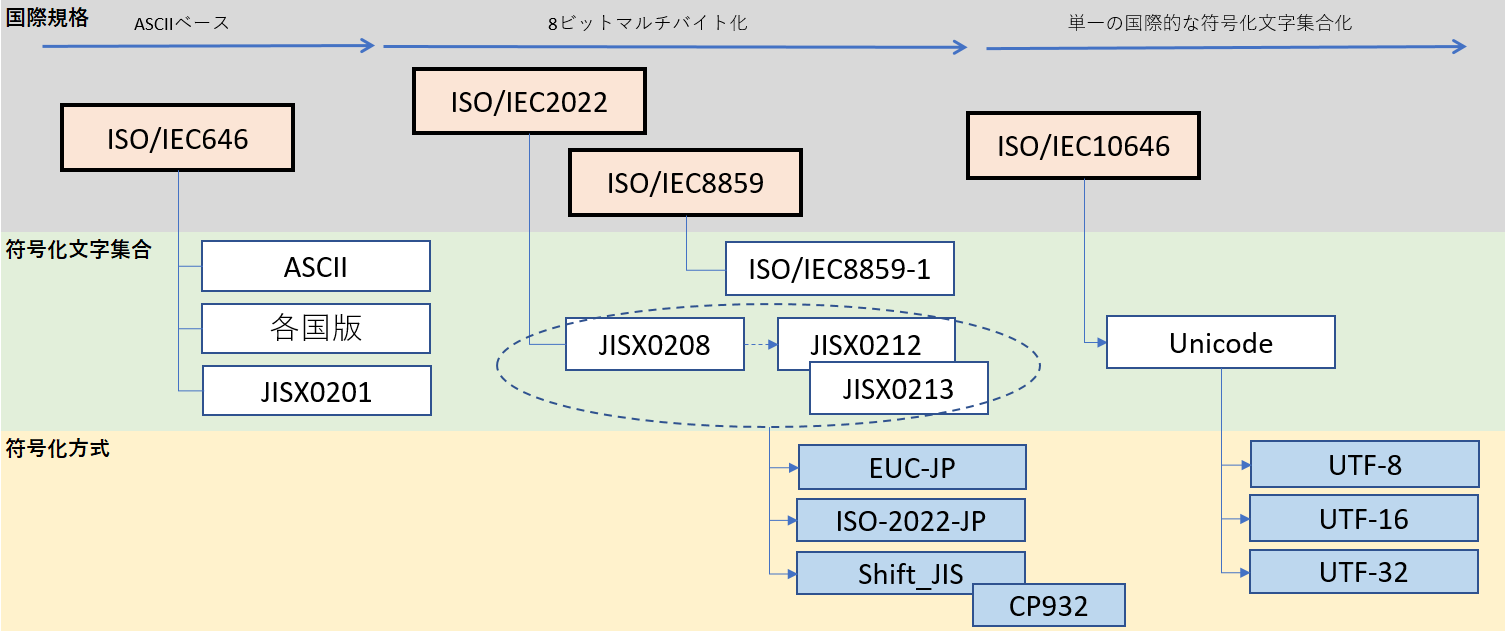
文字集合と文字符号化の関係は?
先程の文字コードの説明の中で、「あれ?UTF-8やUTF-16は?」と思った方もいるかもしれませんが、UTF-8はUnicodeという文字集合をベースに符号化をした「符号化方式」なのです。
もうちょっと噛み砕いいて表現すると以下のようになります。
- 文字集合:英語や日本語など表現する文字の一覧を表したもの
- 符号化文字:文字集合で体系化された文字セットを、どういった形のバイト列にするかという規定のこと
コンピュータは最終的には符号化文字が何であるかを判断して数字の羅列を文字として認識することになりますね。ASCIIコードは「文字集合=符号化文字」となるようですね。
因みにWindowsのメモ帳でUnicodeを選択した場合の符号化方式は「UTF-16」になるようです。( ギークを目指して )
とまあ、文字コードやら文字集合やら符号化方式やらいろいろな言葉がありますが、文字コードが 一般的に使われていて、「文字コード≒文字集合≒符号化方式」と解釈しても問題無いようですね!
以下のサイトの絵が凄く分かり易いです!!
引用: 文字コード(SE-IKEDA)
まとめ
今回は文字コードに関してまとめてみました。
色々な文字コードがありますが、最近は殆どが文字集合体「Unicode」、文字符号化「UTF-8、UTF-16」なんですね。
まあ、これら全体で文字コードと呼んでも良いですが、UnicodeとUTF-8は何が違うの?と聞かれた際には違いを答えられる格好良いですね。
以上です!
参考URL)