「キュー」って何?と聞かれたら英文字の「Q」か数字の「9」を思い浮かべると思います。それか擬態語の「キュ~」とかですかね。。。
とそれはさておき、今回はデータ構造で使う「キュー」と「スタック」に関して解説します。キューだけでなくスタックも?と思うかもしれませんが、この二つはよくセットで出てくるので一緒に覚えましょう。
データ構造とは?
コンピュータにおいてデータを処理する時(アルゴリズム)にデータを保持する必要があります。例えば長い計算をする時に計算途中のデータを一時的に保持する必要がありますよね。
この扱うデータを保持するための方法を決めたものを「データ構造」と呼びます。
例えば社員録は「社員番号、氏名、性別、所属」などのデータを個別に管理するのではなく、一つの集合体として扱うことで処理がし易くなります。
データ構造は色々あって、よく出てくるものとして「配列、キュー、スタック、リスト、木構造」などがあります。では、どのデータ構造を使えば良いのか?それは、何をどう処理したいかによって変わってきます。そのために、データ構造のそれぞれの特徴を抑えることは重要ですね。
では、データ構造として一番分かり易い「配列」を見てみましょう!
配列
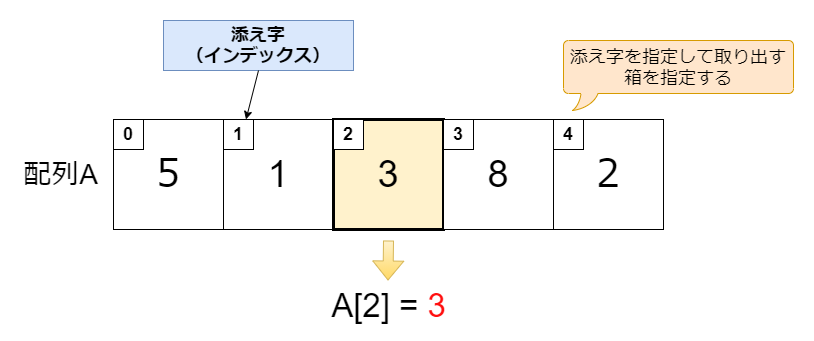
配列とは、同じ型のデータの集まりを順番に箱に入れて並べたデータ構造のことです。つまり、整数なら整数だけを、文字列なら文字列だけを集めたものになります。同じ配列の中に整数と文字を混ぜることはできません。
配列の中のそれぞれの箱のことを「要素」と呼び、この中にデータを入れます。入れたデータの場所を表すために「添え字(インデックス)」があり、添え字を指定することで目的の要素を取り出すことができます。
添え字は「0」から始まり増えていくことが多いですね。
また、配列には添え字を1種類しか使わない「1次元配列」や、添え字を2種類使う「2次元配列」がありますね。
キューとは?
さきほどの配列は添え字を指定することで、取り出したい要素(データ)を選択することができましたね。ただ、配列の場合は添え字を毎回指定しなければならないので、ちょっと複雑ですよね。
今回のテーマである「キューやスタック」は、一時的に保持していたデータを格納したり、取り出すときの手順が決まっているデータ構造です。手順(ルール)が決まっているので、処理としてはシンプルにできますよね。
「キュー(queue)」とは「列」という意味があり、1次元配列で1列に格納されたデータを、格納した順番に取り出すデータ構造となっています。「先に入れたら、先に出す」ので「先入れ先出し方式」と呼び、英語で表現すると「FIFO(First In First Out:ファイフォ)」となります。
また、データを入れることを「enqueue(エンキュー)」と呼び、データを取り出すことを「dequeue(デキュー)」と呼びます。
下にキューのイメージを表現してみました。入れた順番に出てくるので、トコロテンみたいと表現されるみたいですね。

使われ方
では、キューはどんな時に使われるのでしょうか?
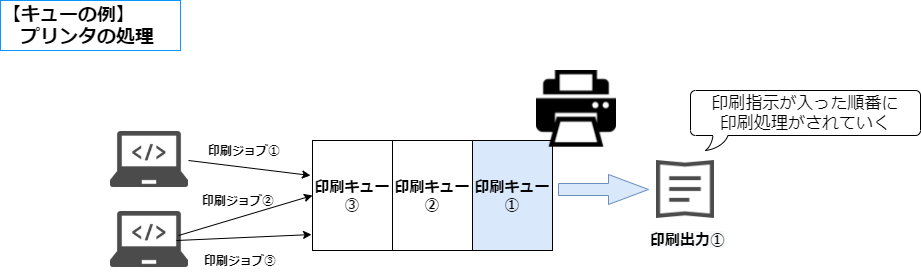
キューは、ディスクの入出力やOSのタスク管理などで使われるようですが、分かり易いのはプリンタからの印刷処理ですね。
下の図にあるように、複数のPCから印刷指示(ジョブ)があった場合、プリンタ自体は同時に複数の印刷をできないので、指示があった順番(下の例だとジョブ①、②、③の順)に印刷処理をしていきます。印刷スプーラなんて呼ばれていますね。
スタックとは?
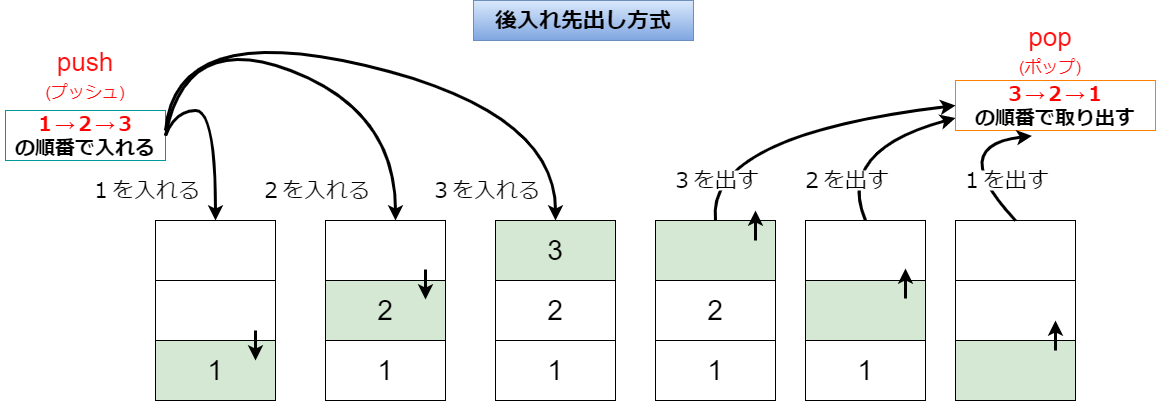
一方、スタックとは「積み重ね」という意味になり、1次元配列で格納されたデータがキューとは逆に、最後に入れたデータから先に取り出すデータ構造になります。つまり、常に一番新しいデータから順番に使う構造になっています。
スタックは「後に入れたら、先に出す」ので「後入れ先出し方式」と呼び、英語で表現すると「LIFO(Lat In First Out:ライフォ)」となります。
また、データを入れることを「push(プッシュ)」と呼び、データを取り出すことを「pop(ポップ)」と呼びます。
キューと違って、若干複雑な感じがしますね。
使われ方
では、スタックはどんな時に使われるのでしょうか?
スタックはCPUのレジスタやプログラムの実行中に他の関数を呼び出す時(再帰関数)に使われたりします。
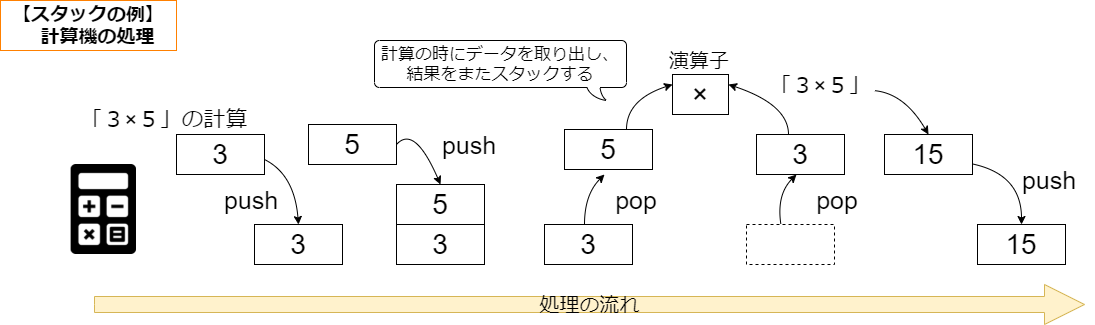
下の図にあるように、計算機で計算する時に、計算に使う値だったり、計算途中の値を一時的にスタックし、後で計算途中のデータを呼び出して、計算に使ったりしますね。
スタックは現在のコンピュータシステムにおいて広範囲で使われているようですね。
まとめ
今回はデータ構造であるキュー、スタックに関して解説しました。データ構造としてはそれほど難しくは無いですが、コンピュータの世界においてよく使われるものなんですね。
キューとスタックがどっちか分からなくなってしまいがちなので、間違えずに覚えましょう。私はキューは「Q」なので、文字のイメージ的にどんどんデータが流れていく感じなので、順番にデータが流れる方だな、と覚えています(かなり強引...)。ビリヤードの棒(キュー)がボールを付いて押し出すイメージで例えられたりもしているようですね(こっちの方が覚えやすい)。
それと、「仕事がスタックしてる...」といった表現することがありますが、これは物事が行き詰って立ち往生したり、停滞してお手上げ状態になったりすることを意味していて、英語では「stuck」となります。今回のスタックは「stack」なので、違うということも覚えておきましょう。
データ構造は他にリスト構造、木構造もあります。
木構造に関しては以下の記事で解説してますので、併せて読んでみてください。
以上です!