「スクレイピング」とは、Webサイトのコンテンツから情報を収集し、処理する仕組みです。
Webサイトのコンテンツには文字情報やリンク情報、画像情報などがありますので、このようなコンテンツから必要な情報を集めて、有効活用しよう!というものです。
今回はこのスクレイピングの仕組みやメリットなどを解説していきます!
スクレイピングとは?
スクレイピングは英語だと「scraping」となり、日本語では「引っかく、書き出す」という意味となります。
Webサイト上のコンテンツをデータとして書き出して(収集して)、そのデータを解析して、必要な部分を取り出したり、加工して必要な処理を行う、というものです。
Web上のコンテンツを対象とするので、Webスクレイピングなんて呼び方もしますね。
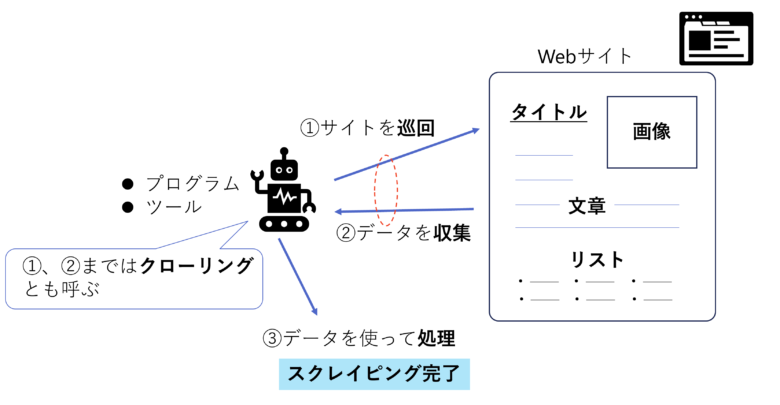
スクレイピングは大きく3つのステップになります。
スクレイピングのステップ
- スクレピングツールやプログラムがサイトを巡回する
- Webサイトからデータを収集する
- 収集したデータを使ってデータの加工や後続処理をする
使い方の例としては、膨大なインターネット上の情報を使ったマーケティングやニュースサイトの情報のまとめ、トレンド分析などがありますね。
メリット
スクレイピングのメリットは、数多の情報から自分の欲しい情報だけを抽出して取得、整理ができることですね。
また情報量が膨大な時にも、自動的に情報を収集してくれるスクレイピングは非常に役に立ちます。
これにより、時間や作業の削減ができますし、単純作業からの脱却もできますね!
注意点
スクレイピングはインターネット上の情報を使いますので、Webサイトの利用規約や著作権などは十分確認しておかないと、迷惑行為となったり、利用規約や法律に抵触したりする恐れがありますので、注意が必要です!
Webサイトの中には、利用規約にスクレイピングが禁止と明言しているサイトもあります。
また、アクセスする側のサイトにも負荷をかけることになりますので、一度に何回もアクセスしないなどの考慮も必要ですね。
クローリングとの違い
Webサイトの情報を収集、と聞くと「クローリング」という言葉も出てくることがあります。
スクレイピングとの違いは、以下のようになります。
クローリングの特徴
- クローリングは様々なWebサイトを定期的に巡回して情報を収集することが目的
- Googleなどの検索エンジンがサイトのコンテンツを発見し、検索エンジンのインデックスに登録することを目的
- スクレイピングはデータ収集後の処理までを行う
下にスクレイピングの流れを図にしてみました。
具体的な仕組みと流れ
では、スクレイピングのもうちょっと具体的な仕組みを見てみましょう。
前提としてスクレイピングを行うには専用ツールやサービスを使うかPythonやJavaScriptなどプログラミング言語を使って自分で作るかがあります。
自前でプログラムした方が自由度は高いのかな、と思います。
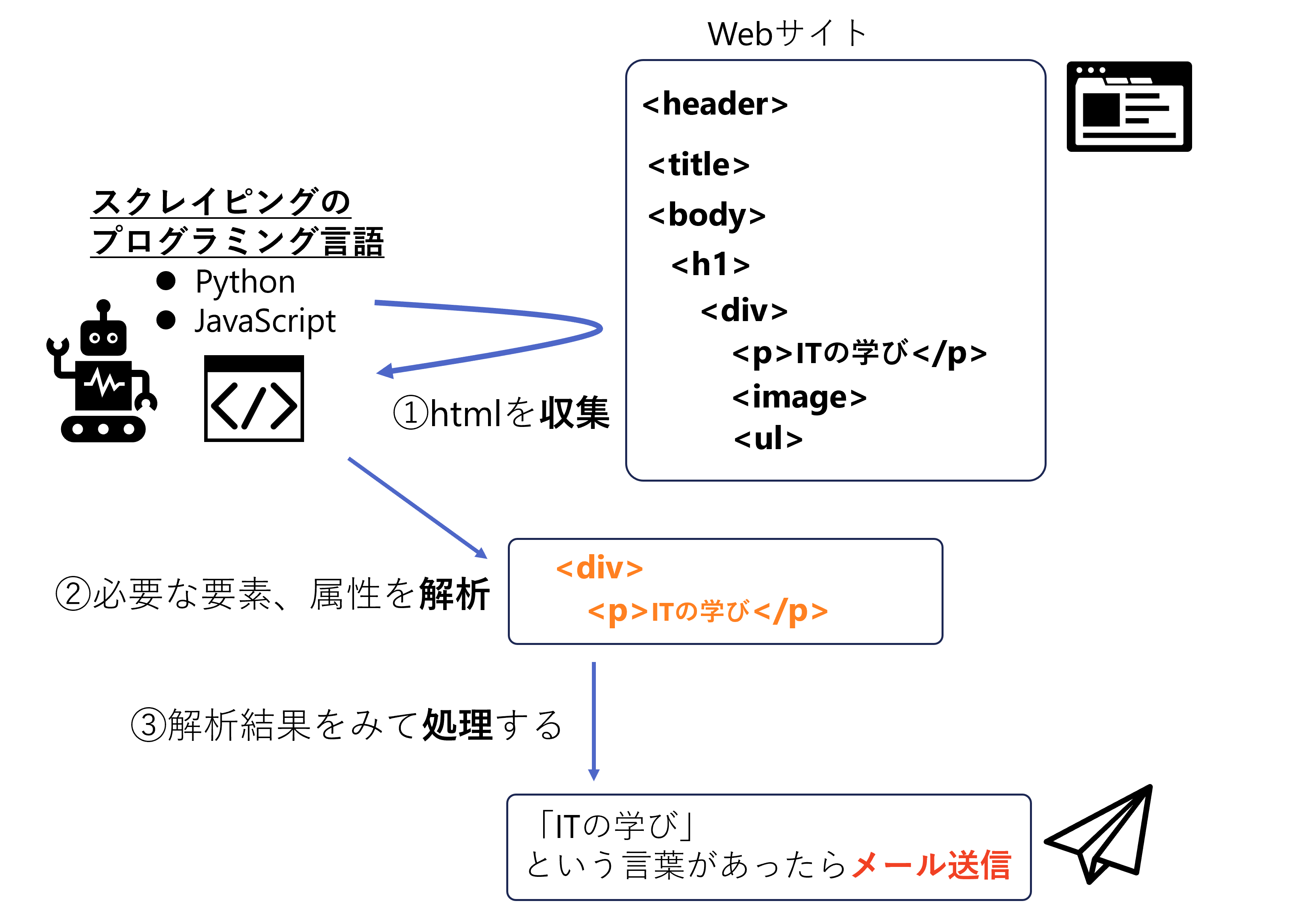
例えば、サイトに「ITの学び」という言葉あったらメールでサイト情報を送ってくれる、という仕組みを作るとした場合は以下のような仕組みを作ります。
スクレイピングの作成
- Webサイトのhtmlの情報を丸ごと取得する
- htmlのタグ(header、title、divなど)の情報をそれぞれ、分解して、中身を解析(確認)する
- 条件文を作り、もしも「ITの学び」という言葉があったら、自分にメールを送るようなロジックを作る
- 上記の流れを5分に一回実行するような設定をする(ポーリングみたいなもの)
上記の流れでしたらPytyonで作っても、数十行のプログラムで済みますので、意外と簡単にできちゃいますね。
まとめ
今回はWebサイトにおけるスクレイピングに関して解説しました。
スクレイピングのまとめ
- Webコンテンツのデータを収集、分析、処理を行って、時間や業務を効率化するための仕組み
- Webサイトの利用規約や著作権などは十分確認した上で行う
- クローリングとの違いはデータ収集後の処理まで行う点
スクレイピングの使い方は色々あって、私はスポーツの予約サイトで空きが出たら、それを自分のLINEに通知してくれるようなプログラムを作って使ったりしてます。
しかも、AWS上の無料枠で動かしていたりするので、巡回の間隔を短くするとデータ量が多くて有料になっちゃうので、ちびちびスクレイピングしてます(笑)
スクレイピングは定期的に実行するので、ポーリングも要素もあります。ポーリングに関しては以下の記事でも解説してますので、併せて読んでみてください。
以上です!